
PVFS(Parallel Virtual File System) 설정 방법
작성자 정보
- 웹관리자 작성
- 작성일
컨텐츠 정보
- 5,527 조회
- 0 추천
-
목록
본문
|
표 1 클러스터 사양 | ||||||||||||||||||||||
|
PVFS를 구현하기 위해서 필요한 파일 - PVFS-1.5.0 - pvfs-kernel-0.9.0 - ftp://mirror.chpc.utah.edu/pub/pvfs/ <-- 다운 사이트 |
|
[root@ime /root]# cp pvfs-1.5.0.tgz pvfs-kernel-0.9.0.tgz /usr/src [root@ime /root]# cd /usr/src [root@ime /usr/src]# tar xvzf pvfs-1.5.0.tgz [root@ime /usr/src]# tar xvzf pvfs-kernel-0.9.0.tgz [root@ime /usr/src]# ln -s pvfs-1.5.0 pvfs
[root@ime /usr/src]# cd pvfs [root@ime /usr/src/pvfs-1.5.0]# ./configure [root@ime /usr/src/pvfs-1.5.0]# make [root@ime /usr/src/pvfs-1.5.0]# make install [root@ime /usr/src/pvfs-1.5.0]# cd ../pvfs-kernel-0.9.0 [root@ime /usr/src/pvfs-kernel-0.9.0]# ./configure --with-libpvfs=./pvfs/lib [root@ime /usr/src/pvfs-kernel-0.9.0]# make [root@ime /usr/src/pvfs-kernel-0.9.0]# make install [root@ime /usr/src/pvfs-kernel-0.9.0]# cp pvfs.o /lib/modules/2.2.16/misc |
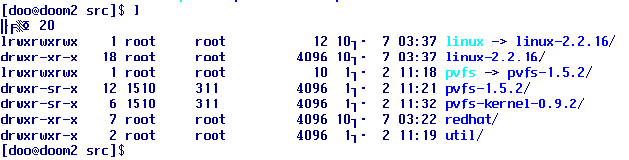
|
[root@ime /]# mkdir /pvfs-meta [root@ime /]# cd /pvfs-meta [root@ime /]# /usr/local/bin/mkmgrconf
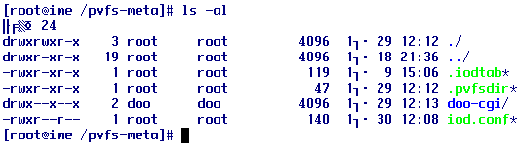
This script will make the .iodtab and .pvfsdir files in the metadata directiory of a PVFS file system. Enter the root directory(metadata directory): /pvfs-meta Enter the user in of directory: root Enter the group id of directory: root Enter the mode of the root directory: 777 Enter the mode of the root directory: doom1 Searching for host...success Enter the port number on the host for manager: (Port number 3000 is the default) 3000 Enter the I/O nodes:(can use form node1, node2, ...or nodename #-#, #, #) doom1, doom2, doom3, doom4 Searching for hosts...success I/O nodes: doom1 doom2 doom3 doom4 Enter the port number for the iods: (Port number 7000 is the default) 7000 Done! [root@ime /pvfs-meta]# ls -al
그림 3과 같이 mkmgrconf 파일을 실행하여 설정을 마쳤을 경우 .iodtab, .pvfsdir 파일 숨겨진 형태로 자동으로 생성한다. |

|
[root@ime /]# mkdir /pvfs-data [root@ime /]# chmod 700 /pvfs-data [root@ime /]# chown nobody.nobody /pvfs-data [root@ime /]# cp /usr/src/pvfs/system/iod.conf /etc/iod.conf [root@ime /]# ls -al /etc/iod.conf |
|
[root@ime /]# /usr/local/sbin/mgr [root@ime /]# /usr/local/sbin/iod |
|
[root@ime /]# /usr/local/bin/iod-ping -h doom1 doom1:7000 is responding [root@ime /]# /usr/local/bin/mgr-ping -h doom1 doom1:3000 is responding
|

|
[root@ime /]# mkdir /mnt/pvfs [root@ime /]# touch /etc/pvfstab [root@ime /]# chmod a+r /etc/pvfstab
[root@ime /]# /bin/mknod /dev/pvfsd c 60 0 [root@ime /]# /sbin/insmod pvfs [root@ime /]# /usr/local/sbin/pvfsd [root@ime /]# /sbin/mount.pvfs doom1:/pvfs-meta /mnt/pvfs |

|
[root@ime /]# cp /etc/iod.conf /mnt/pvfs [root@ime /]# more /mnt/pvfs/iod.conf #Blank IOD config file -- IOD will use builtin defaults [root@ime /]# /usr/local/bin/pvstat /mnt/pvfs/iod.conf /mnt/pvfs/iod.conf: base = 0, pccount = 4 , ssize = 65536 위 내용을 클러스터를 구성하는 각 컴퓨터마다 전부 설치한다.
그림 6의 설정은 컴퓨터를 재부팅했을 경우 다시 클러스터를 구성하는 모든 컴퓨터에서 똑같이 실행해야 PVFS가 제대로 작동하게 된다. 그러나 이런 불편한 점을 스크립 화일을 이용臼?간편하게 설정을 할 수 있고, 스크립 파일을 /etc/rc.d/rc.local 파일 내용에 추가하면 부팅 시 자동으로 설정할 수 있다. 그러나 필자는 그렇게 하지 않고 클러스터의 모든 컴퓨터가 부팅완료 했을 경우에 pvfsexe 스크립 파일 하나를 실행하여 PVFS가 작동하도록 하였다.
|
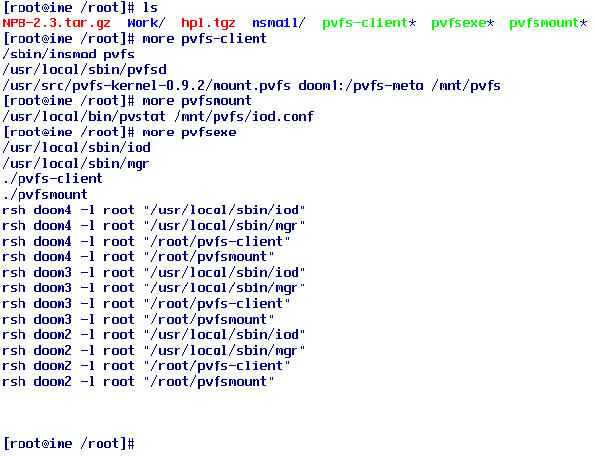
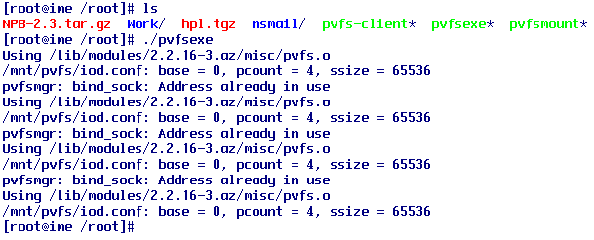

|
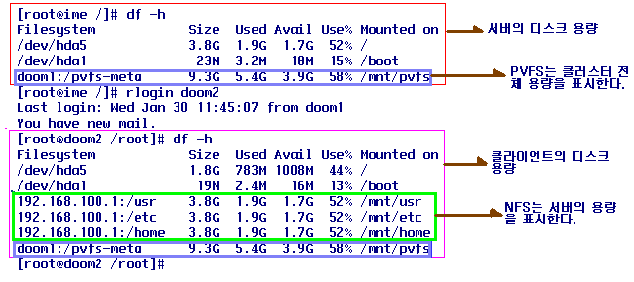
PVFS(Parallel Virtual File System)은 표면적인 작동은 NFS(Network File System)과 같아 보인다. 그러나 내부적으로 동작하는 방법은 커다란 차이가 있다.
그림 9는 클러스터에서 서버노드와 클라이언트노드의 디스크요량을 표시한 것으로 위 붉은색 상자안의 내용이 서버의 디스크 용량으로 서버는 3.8G로 되어 있고, 아래 분홍색 상자 안의 클라이언트노드로 디스크 용량은 1.8G이다. |
|
본 글에서는 편의상 존댓말을 사용하지 않았으며, 끝으로 본 글을 인용 및 참고로 인해 불이익을 당한 것에 대한 책임을 절대로 지지 않음을 알려드립니다.
현재 필자는 표1의 컴퓨터를 이용하여 과학계산용(HPC) 클러스터와 NAT 방식의 부하분산 클러스터를 같이 구현하여 사용하고 있으며, 클러스터의 파일 시스템을 더 편하게 관리하기 위해서 PVFS를 사용하게 되었다. 그러면 이제부터 클러스터와 PVFS의 관계에 대해 언급하겠는데, 필자의 어설픈 생각을 바로 잡아 주실 분은 메일을 통해 의견을 보내주시기 바랍니다.
가 필요했던 것이다. 표 2를 보면 210.106.86.97 IP가 거의 모든 줄에 들어가 있는 것을 볼 수 있다.
표 2 NAT 방식 IP 설정내용 |
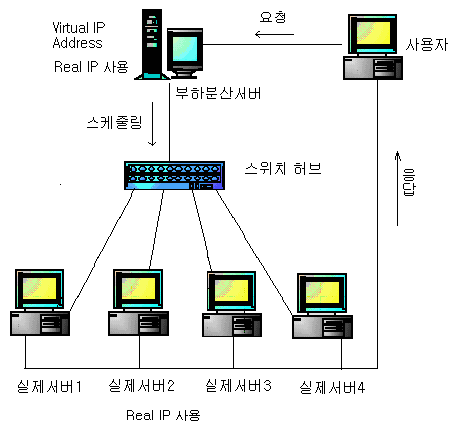
이 IP의 사용 목적은 외부에서 접속했을 때 표면적으로 보여지는 IP로 조금 다르지만 예를 들어 daum에 접속하기 위해서는 www.daum.net 이라는 도메인을 사용하지만 IP는 하나가 아닌 여러 개를 사용한다.
즉, 여러 대의 컴퓨터를 사용하기 때문에 각각의 컴퓨터에 IP가 있지만, 표면적인 것은 하나로 보이는 것이다.
설명이 조금 부족한 듯 한데, 머리에는 맴돌지만 정확히 어떻게 표현해야 할지 모르겠다.
그래서 다시 한번 설명해 보면 어떠한 단체에는 단체를 대표할 수 있는 명칭이 있다.
예를 들어 daum 카페에서와 같이 음악나라, 동창회, 리눅스 사모회 등 각 단체의 고유 명칭이 있다.
하지만 단체를 구성하는 것은 개성 있는 개인 여러 명이 모여 있기 때문에 하나의 단체가 된 것이다.
LVS도 이와 같이 여러 대의 컴퓨터에 각각 설정한 IP가 있지만 그 컴퓨터가 하나의 시스템이 되기 위해 사용할 IP가 필요한 것이다.
그래서 표 2에서 210.106.86.97이 하나의 시스템으로 동작하기 위해 사용한 IP가 되며, 그 밑의 192.168.100.1∼3까지의 IP가 각 컴퓨터의 IP인 것이다.
따라서 필자가 말하고 싶은 것은 LVS를 대표하는 IP가 서로 다른 IP를 사용한 컴퓨터를 묶기 위한(클러스터링) IP이며, LVS내의 여러 컴퓨터가 알아들을 수 있는 IP가 되는 것이다. 그래서 필자는 LVS에서는 IP를 클러스터링 한다고 말하고 싶은 것이다.
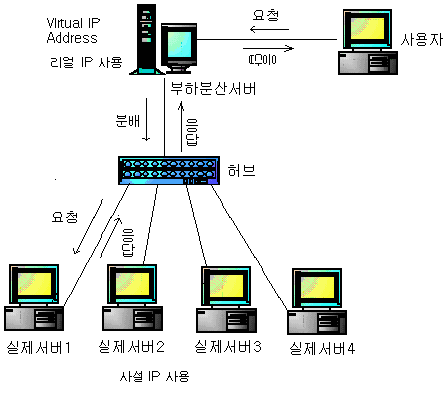
세 번째로 PVFS에 대해 언급하겠다. 클러스터에서 클러스터링을 하는 것은 용도와 기능에 따라 다르다.
하지만 위 두 가지 클러스터는 File System을 배제한 클러스터이다.
하지만 클러스터를 구현해 본 분들은 알겠지만 그럼 File System은 어떻게 묶어야 하는가에 관심을 갖게 된다. LVS의 경우에는 중복된 html 파일을 모든 컴퓨터에 복사하여 사용하게 된다.
이렇게 되면 파일 관리에 많은 어려움이 있고 특히 수정, 삭제, 업데이트, 복사 등의 작업을 할 경우 상당한 작업 시간이 필요하면서 단순한 작업을 해야한다.
이러한 불편을 덜기 위한 것이 NFS이다.
그러나 위에서 언급했듯이 NFS와 PVFS는 엄연한 차이가 있다.
PVFS는 독립적으로 떨어져 있는 하드디스크를 클러스터링하기 위해 사용한 것이다.
필자는 언뜻 소프트웨어적인 RAID라고 생각했고 구현한 결과 그림 9와 같이 확인할 수 있었다.
그러나 구현해 본 분들은 알겠지만 PVFS가 실행되고 있는 상태에서 하드디스크의 어떤 부분이라도 상관없이 아무곳에 파일 저장하면 병렬로 되는가라고 생각할지 모르겠지만, 결론부터 말하면 그렇지 않다.
PVFS는 /mnt/pvfs 또는 /pvfs-meta 디렉토리에 저장해야 여러 대의 컴퓨터에 병렬로 저장하게 되는 것이다. PVFS의 동작을 살펴보면 먼저 필요한 것이이 metadata server, I/O server가 필요하다.
metadata server의 주요 역할은 파일 및 디렉토리 위치, 파일 소유자, 여러 대의 컴퓨터의 어느 위치에 분산되어 저장되어 있는 정보를 갖고 있는 metadata를 관리한다.
그리고 metadata server가 실행하기 위한 데몬은 mgr이다.
I/O server가 실행하기 위한 데몬은 iod 이며, 역할은 여러 대의 컴퓨터에 분산 저장되어 있는 파일 및 디렉토리 접근을 제어하는 것으로 읽고, 쓰기, 저장, 검색을 담당하게 된다.
즉, PVFS는 하드디스크를 RAID와 같이 하나로 묶어주는 역할을 하는 것으로 다르게 생각하면 PVFS를 하나의 클러스터라고 생각할 수 있으며, 클러스터링 하는 대상이 하드디스크 인 것이다.
현재 필자는 PVFS를 구동시켜 PVFS 디렉토리에 계정을 생성하여 몇 개의 html 문서를 저장하여 테스트 중이다. PVFS를 이용하면 LVS에서의 중복된 파일을 각각의 컴퓨터에 복사, 삭제, 수정해야 하는 불편이 줄어들게 되는데, 파일 하나를 저장하면 클러스터내의 다른 컴퓨터에 복사하지 않아도 모든 노드에서 인식하게 되며, 읽기, 쓰기를 마음대로 할 수 있게 된다.
이러한 편리한 이점 때문에 cgi 및 DB 생성 파일을 PVFS에 저장하게 된다면 수정, 삭제, 복사, 업데이트를 하는데 걸리는 시간이 단축된다.
마지막으로 클러스터는 사용 용도에 따라 구현 방법이 다르다는 것을 지금까지 말해왔다.
그동안 클러스터는 과학계산용(HPC), 부하분산(LVS), 고가용성(언급을 안 했음)이 있지만 PVFS도 개인적인 관점으로는 하나의 클러스터라고 볼 수 있으며, 구현에 있어서 클러스터링하는 대상이 다르다는 것을 말해 왔다. 그동안의 클러스터는 완전히 하나의 시스템이다라고 말하기에는 File System 부분 때문에 미약했다. 하지만 PVFS가 등장하면서 클러스터가 점점 하나의 시스템으로 되어 가고 있다.
참고로 필자의 클러스터는 HPC + LVS(NAT 방식) + PVFS 이며 앞으로 고가용성 클러스터를 적재함으로써 더욱 완벽한 클러스터를 구현하려고 한다.
관련자료
-
이전
-
다음


